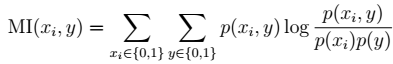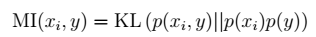机器学习10--学习理论的基础知识
文章目录
机器学习10—学习理论的基础知识
本章:模型选择(交叉选择的方法)—>特征选择。
模型选择
- 设可选的模型集合为:
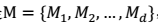 ,那么 SVM、 logistic
,那么 SVM、 logistic
回归、神经网络等模型都包含在 M 中。 - 训练集使用 S 来表示
- 任务:从 M 中选择最好的模型
方法一:简单交叉验证(数据集大)

- 测试集的比例一般占全部数据的 1/4-1/3。30%是典型值。
- 由于测试集是和训练集中是两个世界的,因此我们可以认为这里的经验错误接近于泛化错误。
- 得到的最好模型,在全部数据上重新训练的到所需模型。
方法二:k-折叠交叉验证(数据集小)

- 简而言之,这个方法就是将简单交叉验证的测试集改为 1/k,每个模型训练 k 次,测试 k 次,错误率为 k 次的平均。
- 一般讲k 取值为 10
- 数据集非常小的时候:极端情况下,k 可以取值为 m,意味着每次留一个样例做测试,这个称为 leave-one-out cross validation。
特征选择
- 其实,很多特征对于结果是无用的,想剔除 n 中的无用特征。n 个特征就有$2^n$种去除情况(每个特征去或者保留)。属于NP难问题。
- 本节主要将该问题简化:NP难$2^n$—>$n^2$—>$n$
第一种:启发式搜索方法:前向搜索和后向搜索$O(n^2)$
$时间 复杂度为O(n + (n − 1) +(n − 2) + ⋯ + 1) = O(n^2)$。
前向搜索

后向搜索
先将 F 设置为{1,2,..,n},然后每次删除一个特征,并评价,直到达到阈值或者为空,然后选择最佳的 F。
第二种:过滤特征选择(Filter feature selection)$O(n)$
过滤特征选择方法的想法是针对每一个特征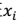 ,i 从 1 到 n,计算
,i 从 1 到 n,计算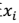 相对于类别标签y的信息量S(i),得到 n 个结果,然后将 n 个S(i)按照从大到小排名,输出前 k 个特征。显然,这样复杂度大大降低,为 O(n)。
相对于类别标签y的信息量S(i),得到 n 个结果,然后将 n 个S(i)按照从大到小排名,输出前 k 个特征。显然,这样复杂度大大降低,为 O(n)。
1、 $x_i $是 0/1 离散值的时候 :
互信息(Mutual information)公式:
2、$x_i $是多个离散值
注: